Design a Search Engine: Architecture and Best Practices
Building a search engine from the ground up requires understanding complex systems that process billions of documents, respond to queries in milliseconds, and rank results with precision. Whether you're creating an enterprise search tool, a specialized vertical search engine, or exploring how Google operates under the hood, knowing how to design a search engine provides invaluable insights into information retrieval, distributed systems, and user experience optimization. This comprehensive guide explores the architectural components, algorithms, and best practices that power modern search technology.
Core Components of Search Engine Architecture
When you design a search engine, you're essentially building four fundamental subsystems that work in harmony: crawling, indexing, query processing, and ranking. Each component serves a distinct purpose while feeding into the next stage of the pipeline.
The crawler (or spider) systematically discovers and fetches documents from the web or your data sources. This component must handle rate limiting, respect robots.txt files, manage distributed crawling across thousands of machines, and prioritize which pages to crawl first. Effective search engine architecture relies on intelligent crawling strategies that balance comprehensiveness with efficiency.
Indexing transforms raw documents into searchable data structures. This involves:
- Parsing HTML, PDF, and various document formats
- Extracting text and metadata
- Tokenizing content into searchable terms
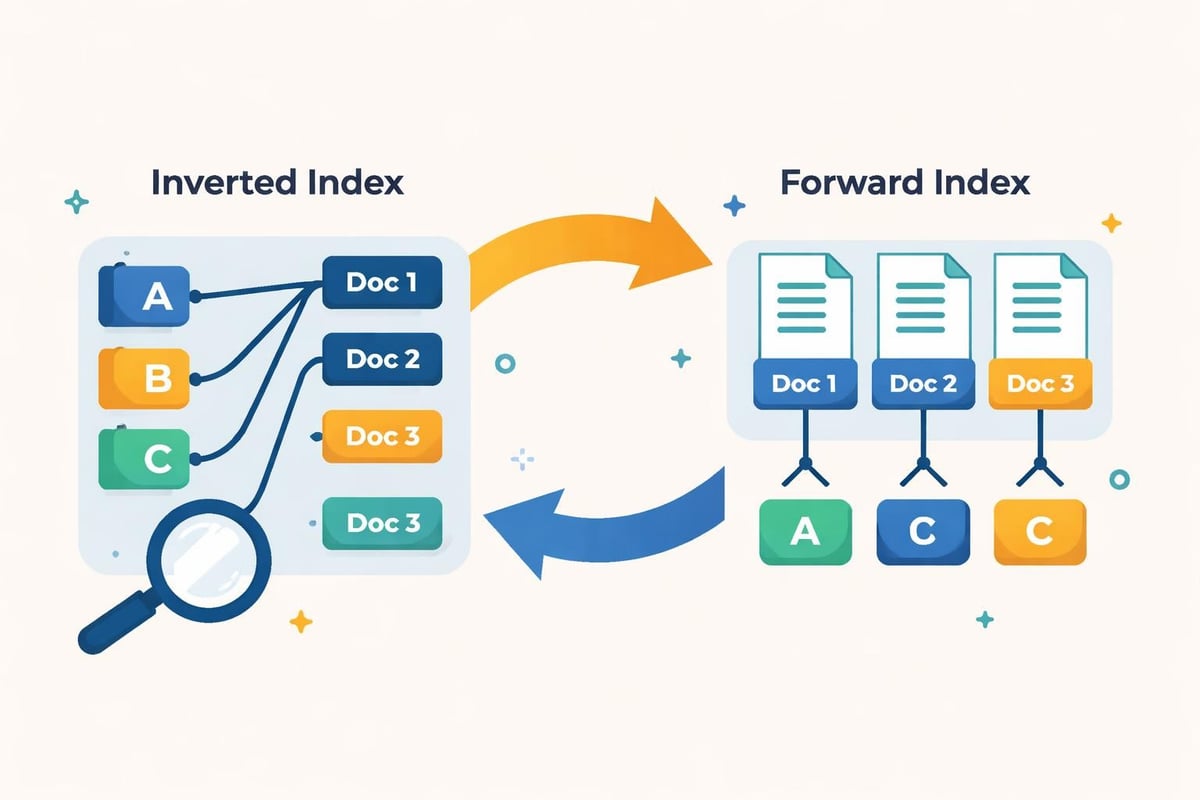
- Building inverted indexes that map terms to documents
- Storing document content for snippet generation
The query processor interprets user searches, expanding abbreviations, correcting spelling, and understanding intent. It transforms natural language queries into structured requests that can be executed against your index efficiently.
Ranking algorithms determine which results appear at the top. Modern systems combine multiple signals: textual relevance, document authority, user engagement metrics, freshness, and personalization factors. The challenge lies in balancing these competing signals to deliver the most useful results.
Building the Crawling Infrastructure
The crawling phase determines which content your search engine knows about. To design a search engine that scales, you need intelligent crawling policies that maximize coverage while respecting resource constraints.
Distributed Crawling Strategy
Modern search engines distribute crawling across thousands of machines. Each crawler instance manages:
- URL frontier: A priority queue of URLs waiting to be crawled
- DNS resolution cache: Reducing lookup overhead
- Politeness policies: Limiting requests per domain
- Duplicate detection: Avoiding crawling the same content multiple times
URL prioritization algorithms determine which pages to crawl first. PageRank-based approaches prioritize authoritative pages, while freshness-focused strategies re-crawl frequently updated content more often.
Handling Scale and Politeness
| Challenge | Solution |
|---|---|
| Billions of URLs | Distributed hash table for URL frontier, partitioned by domain |
| Respect server load | Per-domain rate limiting, exponential backoff |
| Network efficiency | Batch DNS lookups, HTTP pipelining, compression |
| Freshness vs. coverage | Adaptive re-crawl scheduling based on change detection |
Your crawler must also handle edge cases: redirects, authentication requirements, dynamically generated content, and robots.txt compliance. Modern crawlers execute JavaScript to render single-page applications, adding computational overhead but capturing more of today's web.
Designing the Indexing System
The indexing pipeline transforms unstructured content into queryable data structures. When you design a search engine, the index is your core data store that determines query speed and result quality.
An inverted index maps each term to the list of documents containing that term, along with position information for phrase matching. For the term "design," your index might store:
design → [doc1: positions[3, 45, 127], doc2: positions[12, 89], doc5: positions[2, 67, 103]]
Index Construction Pipeline
- Document processing: Extract text, metadata, and structure
- Tokenization: Split text into searchable units (words, n-grams)
- Normalization: Lowercase conversion, stemming, lemmatization
- Stop word filtering: Remove common words (optional, many modern engines keep them)
- Index building: Create inverted lists with positional information
- Compression: Reduce storage using techniques like variable byte encoding
Forward indexes complement inverted indexes by mapping documents to their terms. This enables efficient snippet generation and document analysis. Together, these structures support fast query execution and rich result presentation.
Modern indexing systems partition data across machines using sharding strategies. Document-based sharding distributes complete documents across servers, while term-based sharding splits the index by vocabulary. The choice impacts query distribution patterns and fault tolerance characteristics.
Query Processing and Understanding
Transforming user queries into actionable search requests requires sophisticated natural language processing. To effectively design a search engine, you must bridge the gap between how users express information needs and how documents are indexed.
Query Analysis Techniques
Spell correction catches typos using edit distance algorithms and language models. When users search for "seach engine," your system suggests "search engine" by comparing against known terms and query logs.
Query expansion improves recall by adding synonyms and related terms. A search for "automobile" might expand to include "car" and "vehicle," capturing relevant documents that use different terminology.
Intent classification determines whether users want informational content, navigational results, or transactional pages. This classification influences ranking and result formatting.
Optimization Strategies
- Caching: Store results for popular queries, reducing computation
- Query rewriting: Transform complex queries into equivalent, faster forms
- Early termination: Stop processing once you have enough high-quality results
- Tiered indexing: Check fast in-memory tier before hitting disk-based indexes
The query processing flow must balance speed and quality. Users expect sub-second response times, forcing trade-offs between exhaustive search and practical performance.
Ranking Algorithms and Relevance
Ranking determines which documents appear at the top of search results. This is where you design a search engine that truly serves user needs rather than just matching keywords.
Traditional Ranking Signals
TF-IDF (Term Frequency-Inverse Document Frequency) scores documents based on term importance. Terms that appear frequently in a document but rarely across the collection receive high weights. While foundational, TF-IDF alone produces mediocre results.
BM25 improves on TF-IDF by adding term saturation (diminishing returns for repeated terms) and document length normalization. Most modern search engines use BM25 as a baseline text matching score.
Link analysis algorithms like PageRank assess document authority by analyzing the link graph. Pages referenced by many authoritative sources receive higher scores, independent of text matching.
Machine Learning Approaches
Modern systems employ Learning to Rank (LTR) models that combine hundreds of features:
- Text relevance scores (BM25, semantic similarity)
- Popularity metrics (click-through rate, dwell time)
- Document quality signals (grammar, readability, freshness)
- Query-document features (exact matches, entity overlap)
- User context (location, search history, device type)
| Ranking Approach | Strengths | Limitations |
|---|---|---|
| TF-IDF | Fast, interpretable, no training required | Ignores term order, context, authority |
| BM25 | Better saturation handling, standard baseline | Still keyword-focused, no semantic understanding |
| PageRank | Captures authority, spam-resistant | Computation-intensive, vulnerable to link farms |
| Neural rankers | Semantic understanding, context-aware | Slow inference, requires massive training data |
Companies focused on AI visibility understand that ranking in 2026 increasingly involves optimizing for AI-powered search experiences that use neural rankers and large language models to understand context and intent beyond keyword matching.
Building User Interface Components
The search interface determines how users interact with your engine. When you design a search engine, the UI must balance simplicity with powerful functionality.
Essential Interface Elements
Search bar placement matters significantly. Best practices for search engine design recommend prominent, recognizable search boxes with sufficient width for typical queries. Auto-complete suggestions guide users and reduce typos.
Results presentation should display:
- Document title as a clickable link
- URL or breadcrumb path
- Snippet showing query terms in context
- Metadata (date, author, category)
- Rich results (images, ratings, structured data)
Faceted navigation lets users filter by category, date range, content type, or custom attributes. These filters dramatically improve the search experience in domain-specific engines.
Handling Edge Cases
No-results scenarios deserve special attention. Rather than empty pages, show:
- Spelling suggestions for likely typos
- Relaxed matches (fewer required terms)
- Related searches from query logs
- Popular content or category browsing options
Pagination versus infinite scroll affects performance and user behavior. Pagination provides clear boundaries and better for SEO, while infinite scroll works well for image or product search.
Scalability and Performance Optimization
Enterprise-scale search engines must handle millions of queries daily while maintaining sub-second latency. To design a search engine that performs under load, you need distributed architecture and aggressive optimization.
Distributed System Architecture
Replication ensures availability and load distribution. Multiple index replicas serve queries in parallel, with load balancers distributing requests. If one replica fails, others handle the traffic seamlessly.
Sharding partitions the index across machines to exceed single-server capacity. Document sharding assigns complete documents to specific servers, while term sharding distributes the vocabulary. High-level search engine design often combines both approaches in multi-tier architectures.
Caching strategies occur at multiple levels:
- Query result cache: Store complete result sets for popular queries
- Document cache: Keep frequently accessed documents in memory
- Computation cache: Save expensive intermediate calculations
Performance Metrics and Monitoring
| Metric | Target | Impact |
|---|---|---|
| Query latency (p95) | < 200ms | User satisfaction, bounce rate |
| Index freshness | < 15 minutes | Content accuracy, user trust |
| Crawler throughput | 100+ pages/sec | Coverage, freshness |
| Cache hit rate | > 80% | Query cost, server load |
Monitoring these metrics continuously helps identify bottlenecks before they impact users. Anomaly detection alerts you to unusual query patterns that might indicate attacks or system failures.

Security and Quality Considerations
Search engines face unique security challenges. Malicious actors attempt to manipulate rankings, inject spam, and exploit crawlers for DDoS attacks.
Spam Prevention
Content spam includes keyword stuffing, cloaking (showing different content to crawlers versus users), and doorway pages. Detection requires:
- Content quality classifiers trained on labeled spam examples
- Duplicate detection algorithms to identify copied content
- Link graph analysis to spot unnatural linking patterns
- User behavior signals (high bounce rates indicate low quality)
Search injection attacks attempt to manipulate query processing through specially crafted inputs. Sanitize all user input, use parameterized queries, and implement rate limiting to prevent abuse.
Privacy and Ethics
When you design a search engine based on best practices, privacy considerations are paramount. Modern systems must:
- Anonymize query logs after retention periods
- Provide opt-out mechanisms for personalization
- Secure data transmission with HTTPS
- Comply with regulations (GDPR, CCPA)
- Be transparent about ranking algorithms and data usage
Algorithmic bias requires active mitigation. Ranking algorithms can amplify societal biases present in training data. Regular audits, diverse training data, and fairness metrics help ensure equitable results across user demographics.
Specialized Search Engine Types
Not all search engines crawl the web. Specialized variants serve specific use cases with tailored architectures.
Enterprise Search
Internal search engines index corporate documents, wikis, emails, and databases. Challenges include:
- Multiple data formats and sources
- Permission-aware results (only show what users can access)
- Integration with authentication systems
- Real-time indexing for rapidly changing content
Vertical Search
Domain-specific engines (job search, real estate, academic papers) optimize for their niche. They can leverage structured data, specialized ranking factors, and targeted crawling strategies that general-purpose engines cannot.
E-commerce Search
Product search prioritizes conversion over general relevance. Ranking incorporates:
- Product availability and inventory levels
- Pricing and discount information
- Sales velocity and trending items
- Personalized recommendations based on browsing history
Faceted navigation becomes crucial for filtering by brand, price range, ratings, and attributes. Understanding how websites rank across different search contexts helps optimize product discoverability.
Testing and Evaluation Frameworks
Measuring search quality requires both automated metrics and human evaluation. When you design a search engine, rigorous testing ensures continuous improvement.
Offline Evaluation Metrics
Precision measures what fraction of returned results are relevant. Recall measures what fraction of all relevant documents are returned. The F1 score balances both.
Mean Reciprocal Rank (MRR) evaluates ranking quality by averaging the reciprocal rank of the first relevant result. If the first relevant document appears at position 3, the reciprocal rank is 1/3.
Normalized Discounted Cumulative Gain (NDCG) accounts for graded relevance (documents can be highly relevant, somewhat relevant, or not relevant) and position bias (higher positions matter more).
Online Evaluation Techniques
A/B testing compares ranking algorithms by showing different variants to random user subsets. Metrics include:
- Click-through rate on top results
- Time to first click
- Abandonment rate (searches without clicks)
- Reformulation rate (users refining their query)
Interleaving mixes results from two algorithms in a single results page, then analyzes which algorithm's results receive more clicks. This provides faster, more sensitive comparisons than A/B testing.
Advanced Features and Capabilities
Modern search engines extend beyond simple text matching to provide rich, context-aware experiences.
Semantic Search
Neural embeddings represent documents and queries as vectors in high-dimensional space. Cosine similarity between vectors measures semantic relatedness, capturing concepts beyond keyword overlap. Searching for "feline" retrieves documents about "cats" even without exact term matches.
Named entity recognition identifies people, places, organizations, and dates within documents. This enables entity-based search where users find "companies founded by Steve Jobs" rather than just keyword matches.
Multimedia Search
Image search uses computer vision to index visual content. Features include reverse image search, visual similarity, and object detection. Text extracted from images (OCR) supplements visual features.
Video search combines speech recognition transcripts, visual analysis, and metadata. Temporal indexing enables searching within videos and jumping to relevant segments.
Personalization and Context
Search results adapt to individual users based on:
- Location: Local businesses, regional news, geographic relevance
- Search history: Understanding evolving information needs across sessions
- Device type: Mobile users prefer different content formats than desktop users
- Time of day: News freshness matters more in morning searches
Balancing personalization with filter bubbles requires showing diverse perspectives while still prioritizing individual relevance. Organizations focused on building AI-optimized websites recognize that modern search systems increasingly use contextual signals to deliver personalized experiences.
Implementation Considerations and Tools
Building from scratch versus leveraging existing technologies depends on your requirements and resources.
Open Source Solutions
Elasticsearch provides distributed full-text search with RESTful APIs. It handles indexing, querying, and analytics at scale. Built on Apache Lucene, it offers production-ready search with minimal setup.
Apache Solr offers similar capabilities with strong enterprise features like faceting, highlighting, and complex query support. Both Elasticsearch and Solr suit most search applications without custom development.
Whoosh (Python) and Bleve (Go) provide lightweight alternatives for smaller-scale projects where you need more control or simpler deployment.
Custom Implementation Path
Following a step-by-step guide to making a custom search engine makes sense when:
- Existing solutions cannot meet specific performance requirements
- You need proprietary ranking algorithms
- Integration with legacy systems requires custom adapters
- Learning and experimentation are primary goals
The custom path demands significant engineering investment but offers maximum flexibility for unique requirements.
Designing a search engine involves orchestrating complex systems that crawl content, build indexes, process queries, and rank results with speed and accuracy. Whether you're building a specialized vertical search, enhancing enterprise knowledge discovery, or exploring information retrieval concepts, understanding these architectural principles and best practices provides the foundation for creating effective search experiences. Creotivity helps businesses optimize their digital presence for both traditional search engines and emerging AI-powered discovery platforms, ensuring your content reaches users regardless of how they search. Ready to improve your search visibility across all platforms? Reach out to discover how modern AI-driven optimization can transform your online presence.